Introduction
Big Data applications are changing the way we live, think and respond. After reading stories about Google, Twitter, Facebook, Pintrest, Ubers of the world, I have found that these companies are successful because their apps respond to the need of millions of people on this earth. Not only the response is timely, it is often customized meeting a personal need at the moment. It could be a best near-by restaurant within your budget or mobile phone available at cheaper store around you, or even a doctor for fast urgent care. Uses are numerous.
How do they do it? To deliver at scale and respond 24x7, they have built scalable, reliable and secure big data infrastructure that meets need of an agile development team. Agile development teams at these organizations are empowered to unleash innovation at speed of thought. Innovation keeps them alive. They keep on scavenging for best open source technology they can get their hands on so that they can experiment new ideas, build mock-ups, code it close to production standards. There is not much lag between initial code and production code. First time code has to be right code!
I have discussed about Hadoop and Machine Learning throughout the year here . Let me end this year with a blog on how to implement big data apps by realizing product features fast. I will start with what I mean by agility and then discuss visualization driven ideation and mockup methods. This is very important. Businesses need top-notch visualization of big data findings to garner insights, to make useful and timely decisions. Taking cues from ideas, I will discuss implementation choices we have. There, I will discuss web app implementation and modern data infrastructure choices, urging you decide on a framework for development , storage and processing. It is the foundation of what you will build and maintain for years to come. I will touch upon agile development concepts as needed.
Agility
Agile Development fits Big Data development well. Agile methods attempt a useful compromise between no process and too much process, providing just enough process to gain a reasonable payoff at the speed of business. Agile methods have some significant changes in emphasis from engineering methods. The most immediate difference is that they are less document-oriented, usually emphasizing a smaller amount of documentation for a given task. In many ways they are rather code-oriented: following a route that says that the key part of documentation is source code.
Two key characteristics that apply to big data development are - Agile methods are adaptive and people oriented. These two themes advance modern big data application development. Just ask a Google or Uber developer.
Idea
From understanding the background information, we want to learn the following: What is the main point we want to make to our audience? If there are multiple goals, how can we prioritize them? Knowing these answers helps us decide on the hierarchy of ideas to visually emphasize. At this stage, there is very little discussion about the look and feel. That will emerge with time.Sketching out an assortment of thumbnails of potential designs is a good habit. Keep your mind open to different ideas. Trying out ideas with pen and paper saves a lot of time later on because if you identify a bad idea, it’s much less painful to throw it out since you haven’t invested much time and effort.
After sketching ideas, we should experiment with the custom data visualizations by coding proofs-of-concept. Using d3.js is advised but there are many solutions out there. This site is an example of a quick sketch using d3.js to understand how a sketch looked with real data. It doesn’t need to be fancy, just enough to get the concept across so you have time to explore other ideas.
After deciding which ideas are the most promising, we should create a mock--up. At this stage there is plenty of jumping back and forth between sketching, d3.js sketching, and mock-up while refining ideas. Let ideas win consensus from stakeholders and developers at first. This is what should happen during initial set of daily sprints of SCRUM like agile development sessions. Let us not fall into the trap of coding from a sketch and playing around with the style sheets to figure out the design. Separating the design side from the development side is much more efficient. Same person should not do do both tasks. They require different skills and trying to design while developing is difficult, error-prone and frustrating.
Implementation
We are fully aware of LAMP and how open source technology revolutionized web application development for ever. LAMP was used to build prototype of Facebook, Flipkart and so many big data applications that we use today. World has changed since then. MySQL has become NoSQL and PHP has become JavaScript. What are our choices today? There is good news. Following footsteps of LAMP, new frameworks like Mean and Meteor are advancing thought of rapid application development, using base modules like jQuery, HTML5, Node.js and Angular.js. They shorten development time while giving developers control by sharing data,, models and code repositories. This approach is rooted in agile development methodology.
If you want to stay conservative, you can stick with vendors, Cloudera/Hortonworks/MapR/IBM/MongoDB/Cassandra, and keep experimenting with what they offer to meet your need. You still need to keep track of open source offerings that you need to integrate with vendor offerings. You get peace of mind that you can go to someone for help as you design your architecture and start data prep, coding and deployment. If you do not want to go vendor route. you can pick and choose open source modules. You have to tap into right resources ( software/skills ) that can deliver you goods, which may end up being expensive and frustrating. Beauty here is that you devise one blueprint that works for you, so you can keep going for long time to come. This is what Google, Netflix, Facebook and others have in practice. Google has relentlessly innovated sine they solved search/rank problem using GFS ( Google File System ) for Storage and Map Reduce for Computing, decade or more back.
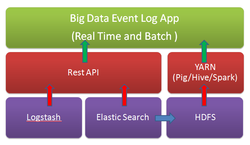
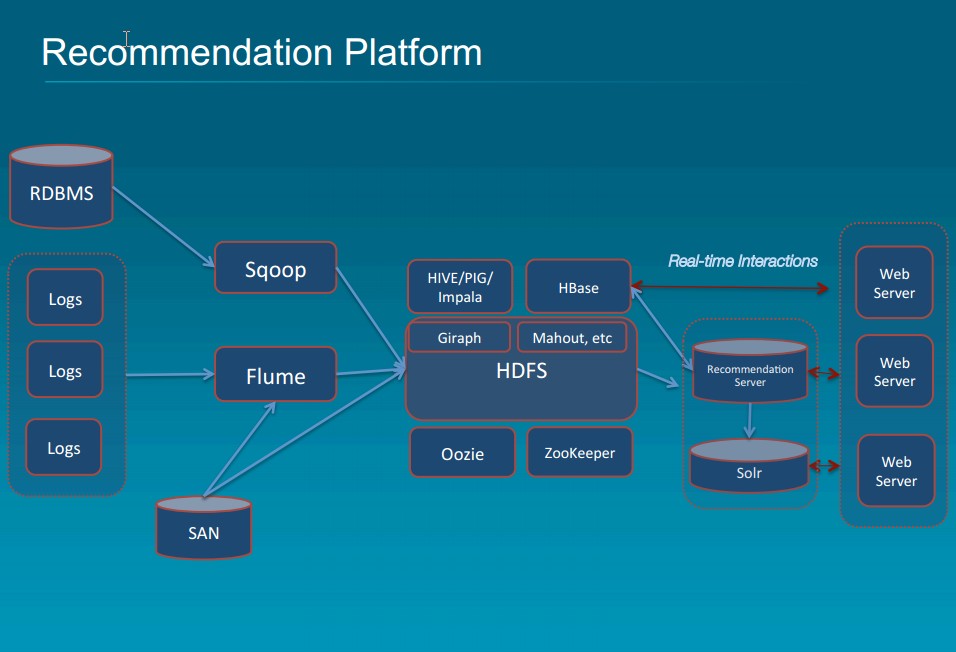
Today, Cassandra and HDFS coupled with multiple execution frameworks, including Spark, Spark Streaming, Spark SQL, Impala, and CQL. Kafka/Storm are used for scalable fault tolerant data ingestion. Once data is ingested, data needs to be accessed and processed. You need transparent mechanism data flow and processing.
The ideal scenario for us would be a single copy of the data to serve all our data needs, but this is very difficult to achieve because the underlying architectures that serve high-volume, low-latency OLTP needs are fundamentally different from those needed to serve the large table scans required in analytical use cases. For example, Cassandra purposely makes it difficult to be able to scan large ranges of data, but allows for low-millisecond access of millions of records per second. On the flip side, the fundamental storage pattern in distributed file systems like HDFS purposely does not index data to allow for low-millisecond access, but uses larger block sizes to allow for very fast sequential access of data to scan billions of records per second.
Streaming engines like Spark Streaming help mitigate the problem by allowing analytics to be performed on the fly as data is ingested into the system. Apache Storm can be used in place of Spark Streaming.
When is the last time you were able to predict every metric that needed to be calculated at project inception? Thus lambda architectures have arisen to allow metrics to be added down the road by recomputing history. One important characteristic of a good lambda architecture is that the system needing to re-compute history should be able to operate quickly on a large dataset without disrupting performance or the low-latency user traffic. Therefore, it is not uncommon to store copy of our data in Parquet format on HDFS, whereas on Cassandra for the low-latency user traffic.
Modern data architecture requires ability to use multiple execution frameworks over the same data. By using open data formats and storage engines, we gain the flexibility to use the right tool for the job, and position ourselves to exploit new technologies as they emerge. Said that, we have many choices. Trick is to look at best practices of what successful companies have deployed and derived best techniques conforming to timing, budget and resources guidelines. If skills are unlimited in supply and there are no budget constraints, you can be best positioned to devise right architecture and process first time. That is rare. You have to keep experimenting and tuning the framework. It is always work in process and 100% agile.
Conclusion
We have only scratched the surface of how this process can be used to solve multiple data engineering problems in the context of Big Data app development - from idea to implementation. I have urged practicing agile methodology. Hopefully, this post provides some useful ideas. If you want to know more about what Big Data apps for enterprise are about, please read famous Forbes article by Edd Dumbill.
Big Data applications are changing the way we live, think and respond. After reading stories about Google, Twitter, Facebook, Pintrest, Ubers of the world, I have found that these companies are successful because their apps respond to the need of millions of people on this earth. Not only the response is timely, it is often customized meeting a personal need at the moment. It could be a best near-by restaurant within your budget or mobile phone available at cheaper store around you, or even a doctor for fast urgent care. Uses are numerous.
How do they do it? To deliver at scale and respond 24x7, they have built scalable, reliable and secure big data infrastructure that meets need of an agile development team. Agile development teams at these organizations are empowered to unleash innovation at speed of thought. Innovation keeps them alive. They keep on scavenging for best open source technology they can get their hands on so that they can experiment new ideas, build mock-ups, code it close to production standards. There is not much lag between initial code and production code. First time code has to be right code!
I have discussed about Hadoop and Machine Learning throughout the year here . Let me end this year with a blog on how to implement big data apps by realizing product features fast. I will start with what I mean by agility and then discuss visualization driven ideation and mockup methods. This is very important. Businesses need top-notch visualization of big data findings to garner insights, to make useful and timely decisions. Taking cues from ideas, I will discuss implementation choices we have. There, I will discuss web app implementation and modern data infrastructure choices, urging you decide on a framework for development , storage and processing. It is the foundation of what you will build and maintain for years to come. I will touch upon agile development concepts as needed.
Agility
Agile Development fits Big Data development well. Agile methods attempt a useful compromise between no process and too much process, providing just enough process to gain a reasonable payoff at the speed of business. Agile methods have some significant changes in emphasis from engineering methods. The most immediate difference is that they are less document-oriented, usually emphasizing a smaller amount of documentation for a given task. In many ways they are rather code-oriented: following a route that says that the key part of documentation is source code.
Two key characteristics that apply to big data development are - Agile methods are adaptive and people oriented. These two themes advance modern big data application development. Just ask a Google or Uber developer.
Idea
From understanding the background information, we want to learn the following: What is the main point we want to make to our audience? If there are multiple goals, how can we prioritize them? Knowing these answers helps us decide on the hierarchy of ideas to visually emphasize. At this stage, there is very little discussion about the look and feel. That will emerge with time.Sketching out an assortment of thumbnails of potential designs is a good habit. Keep your mind open to different ideas. Trying out ideas with pen and paper saves a lot of time later on because if you identify a bad idea, it’s much less painful to throw it out since you haven’t invested much time and effort.
After sketching ideas, we should experiment with the custom data visualizations by coding proofs-of-concept. Using d3.js is advised but there are many solutions out there. This site is an example of a quick sketch using d3.js to understand how a sketch looked with real data. It doesn’t need to be fancy, just enough to get the concept across so you have time to explore other ideas.
After deciding which ideas are the most promising, we should create a mock--up. At this stage there is plenty of jumping back and forth between sketching, d3.js sketching, and mock-up while refining ideas. Let ideas win consensus from stakeholders and developers at first. This is what should happen during initial set of daily sprints of SCRUM like agile development sessions. Let us not fall into the trap of coding from a sketch and playing around with the style sheets to figure out the design. Separating the design side from the development side is much more efficient. Same person should not do do both tasks. They require different skills and trying to design while developing is difficult, error-prone and frustrating.
Implementation
We are fully aware of LAMP and how open source technology revolutionized web application development for ever. LAMP was used to build prototype of Facebook, Flipkart and so many big data applications that we use today. World has changed since then. MySQL has become NoSQL and PHP has become JavaScript. What are our choices today? There is good news. Following footsteps of LAMP, new frameworks like Mean and Meteor are advancing thought of rapid application development, using base modules like jQuery, HTML5, Node.js and Angular.js. They shorten development time while giving developers control by sharing data,, models and code repositories. This approach is rooted in agile development methodology.
If you want to stay conservative, you can stick with vendors, Cloudera/Hortonworks/MapR/IBM/MongoDB/Cassandra, and keep experimenting with what they offer to meet your need. You still need to keep track of open source offerings that you need to integrate with vendor offerings. You get peace of mind that you can go to someone for help as you design your architecture and start data prep, coding and deployment. If you do not want to go vendor route. you can pick and choose open source modules. You have to tap into right resources ( software/skills ) that can deliver you goods, which may end up being expensive and frustrating. Beauty here is that you devise one blueprint that works for you, so you can keep going for long time to come. This is what Google, Netflix, Facebook and others have in practice. Google has relentlessly innovated sine they solved search/rank problem using GFS ( Google File System ) for Storage and Map Reduce for Computing, decade or more back.
Today, Cassandra and HDFS coupled with multiple execution frameworks, including Spark, Spark Streaming, Spark SQL, Impala, and CQL. Kafka/Storm are used for scalable fault tolerant data ingestion. Once data is ingested, data needs to be accessed and processed. You need transparent mechanism data flow and processing.
The ideal scenario for us would be a single copy of the data to serve all our data needs, but this is very difficult to achieve because the underlying architectures that serve high-volume, low-latency OLTP needs are fundamentally different from those needed to serve the large table scans required in analytical use cases. For example, Cassandra purposely makes it difficult to be able to scan large ranges of data, but allows for low-millisecond access of millions of records per second. On the flip side, the fundamental storage pattern in distributed file systems like HDFS purposely does not index data to allow for low-millisecond access, but uses larger block sizes to allow for very fast sequential access of data to scan billions of records per second.
Streaming engines like Spark Streaming help mitigate the problem by allowing analytics to be performed on the fly as data is ingested into the system. Apache Storm can be used in place of Spark Streaming.
When is the last time you were able to predict every metric that needed to be calculated at project inception? Thus lambda architectures have arisen to allow metrics to be added down the road by recomputing history. One important characteristic of a good lambda architecture is that the system needing to re-compute history should be able to operate quickly on a large dataset without disrupting performance or the low-latency user traffic. Therefore, it is not uncommon to store copy of our data in Parquet format on HDFS, whereas on Cassandra for the low-latency user traffic.
Modern data architecture requires ability to use multiple execution frameworks over the same data. By using open data formats and storage engines, we gain the flexibility to use the right tool for the job, and position ourselves to exploit new technologies as they emerge. Said that, we have many choices. Trick is to look at best practices of what successful companies have deployed and derived best techniques conforming to timing, budget and resources guidelines. If skills are unlimited in supply and there are no budget constraints, you can be best positioned to devise right architecture and process first time. That is rare. You have to keep experimenting and tuning the framework. It is always work in process and 100% agile.
Conclusion
We have only scratched the surface of how this process can be used to solve multiple data engineering problems in the context of Big Data app development - from idea to implementation. I have urged practicing agile methodology. Hopefully, this post provides some useful ideas. If you want to know more about what Big Data apps for enterprise are about, please read famous Forbes article by Edd Dumbill.

 RSS Feed
RSS Feed
