Introduction
In this blog, I give an overview of the recommendation engines widely used in Big Data applications. I have reviewed several articles on the web and now write the blog. With Big Data in limelight for sometime now, there is emphasis on the value aspect of Big Data and how to extract it. Not to our surprise, these engines are workhorses and extract value from big data if you consider now value as 4th V after 3Vs of Big Data i.e Volume, Velocity and Variety.
Recommendation systems are quite popular among shopping sites and social network these days. How do they do it ? Basically, the user interaction data available from items and products in shopping sites and social networks are enough information to build a recommendation engine using classic techniques such as Collaborative Filtering. We know map-reduce is a powerful technique for numerical computation and specially when you have to compute large data sets on Hadoop. The numerical computation is foundation of algorithms used to recommend. Cloudera Platform that combines Hadoop framework and Mahout ( algorithms ) is given below.
At its core, recommendation engines sort through massive amounts of data to identify potential user preferences. Recommendation systems changed the way inanimate websites communicate with their users. Rather than providing a static experience in which users search for and potentially buy products, recommender systems increase interaction to provide a richer experience. If the recommendation benefits a supplier, the engine provider i.e recommendation platform owner benefits financially as well. Recommender systems can identify recommendations autonomously for individual users based on past purchases and searches, and on other users' current behavior. This article introduces you to recommender systems and the algorithms that they implement. It also covers how it is being implemented, with examples from open source, Microsoft and Cloudera.
Examples of Recommendation Engines:
LinkedIn, the business-oriented social networking site, forms recommendations for people you might know, jobs you might like, groups you might want to follow, or companies you might be interested in. LinkedIn uses Apache Hadoop to build its specialized collaborative-filtering capabilities.
Amazon, the popular e-commerce site, uses content-based recommendation. When you select an item to purchase, Amazon recommends other items other users purchased based on that original item (as a matrix of item-to-likelihood-of-next-item purchase). Amazon patented this behavior, called item-to-item collaborative filtering.
Hulu, a streaming-video website, uses a recommendation engine to identify content that might be of interest to users. It also uses (offline) item-based collaborative filtering with Hadoop to scale the processing of massive amounts of data. Details of Hulu's online and offline ItemCF architecture are publicly available.
Netflix, the video rental and streaming service, is a famous example. In 2006, Netflix held a competition to improve its recommendation system, Cinematch. In 2009, three teams combined to build an ensemble of 107 recommendation algorithms that resulted in a single prediction. This ensemble proved to be the key to improving predictive accuracy, and the combined team won the prize.
Other sites that incorporate recommendation engines include Facebook, Twitter, Google, MySpace, Last.fm, Del.icio.us, Pandora, Goodreads, and your favorite online news site. Use of a recommendation engine is becoming a standard element of a modern web presence.
Basic Approaches
Most recommender systems take either of two basic approaches: collaborative filtering or content-based filtering.
Other approaches (such as hybrid approaches) also exist.
Collaborative filtering
Collaborative filtering arrives at a recommendation that's based on a model of prior user behavior. The model can be constructed solely from a single user's behavior or — more effectively — also from the behavior of other users who have similar traits. When it takes other users' behavior into account, collaborative filtering uses group knowledge to form a recommendation based on like users. In essence, recommendations are based on an automatic collaboration of multiple users and filtered on those who exhibit similar preferences or behaviors.
For example, suppose you're building a website to recommend blogs. By using the information from many users who subscribe to and read blogs, you can group those users based on their preferences. For example, you can group together users who read several of the same blogs. From this information, you identify the most popular blogs that are read by that group. Then — for a particular user in the group — you recommend the most popular blog that he or she neither reads nor subscribes to.
Another way to view these relationships is based on their similarities and differences, as illustrated in the Venn diagram. The similarities define (based on the particular algorithm used) how to group users who have similar interests. The differences are opportunities that can be used for recommendation — applied through a filter of popularity or likes.
Content-based filtering
Content-based filtering constructs a recommendation on the basis of a user's behavior. For example, this approach might use historical browsing information, such as which blogs the user reads and the characteristics of those blogs. If a user commonly reads articles about Linux or is likely to leave comments on blogs about software engineering, content-based filtering can use this history to identify and recommend similar content (articles on Linux or other blogs about software engineering). This content can be manually defined or automatically extracted based on other similarity methods.
Hybrid Filtering
Hybrid approaches that combine collaborative and content-based filtering are also increasing the efficiency (and complexity) of recommender systems. A simple example of a hybrid system could use combined approaches mentioned above. Incorporating the results of collaborative and content-based filtering creates the potential for a more accurate recommendation. The hybrid approach could also be used to address collaborative filtering that starts with sparse data — known as cold start— by enabling the results to be weighted initially toward content-based filtering, then shifting the weight toward collaborative filtering as the available user data set matures.
Recommendation Engine Algorithms
As demonstrated by the winning approach for the Netflix prize, many algorithmic approaches are available for recommendation engines. Results can differ based on the problem the algorithm is designed to solve or the relationships that are present in the data. Many of the algorithms come from the field of machine learning, a sub-field of artificial intelligence that produces algorithms for learning, prediction, and decision-making.
Pearson correlation
Similarity between two users (and their attributes, such as articles read from a collection of blogs) can be accurately calculated with the Pearson correlation. This algorithm measures the linear dependence between two variables (or users) as a function of their attributes. But it doesn't calculate this measure over the entire population of users. Instead, the population must be filtered down to neighborhoods based on a higher-level similarity metric, such as reading similar blogs.
The Pearson correlation, which is widely used in research, is a popular algorithm for collaborative filtering.
Clustering
Clustering algorithms are a form of unsupervised learning that can find structure in a set of seemingly random (or unlabeled) data. In general, they work by identifying similarities among items, such as blog readers, by calculating their distance from other items in a feature space. (Features in a feature space could represent the number of articles read in a set of blogs, time spent on articles, comments on blogs etc. .) The number of independent features defines the dimensionality of the space. If items are "close" together, they can be joined in a cluster.
Many clustering algorithms exist. The simplest one is k-means, which partitions items into k clusters. Initially, the items are randomly placed into clusters. Then, a centroid (or center) is calculated for each cluster as a function of its members. Each item's distance from the centroids is then checked. If an item is found to be closer to another cluster, it's moved to that cluster. Centroids are recalculated each time all item distances are checked. When stability is reached (that is, when no items move during an iteration), the set is properly clustered, and the algorithm ends.
Calculating the distance between two objects can be difficult to visualize. One common method is to treat each item as a multidimensional vector and calculate the distance by using the Euclidean algorithm. Other clustering variants include the Adaptive Resonance Theory (ART) family, Fuzzy C-means, and Expectation-Maximization (probabilistic clustering), to name a few.
Other algorithms
Many algorithms — and an even larger set of variations of those algorithms — exist for recommendation engines. Some that have been used successfully include:
Bayesian Belief Nets, which can be visualized as a directed acyclic graph, with arcs representing the associated probabilities among the variables.
Markov chains, which take a similar approach to Bayesian Belief Nets but treat the recommendation problem as sequential optimization instead of simply prediction.
Rocchio classification (developed with the Vector Space Model), which exploits feedback of the item relevance to improve recommendation accuracy.
Building a Recommendation Engine
There are several optimizations we can do in those scripts such as Numpy vectorizations , R packages etc. for computing the similarities between items, interests and so on. These similarities when applied to a model emit recommendations for the user on-line ( Solr ) or off-line ( Hbase/Impala ). Hadoop constitutes an integral part of a big data driven recommendation engines of today.
There are many open source offerings to build recommendation engines. I hereby give examples that cover both Microsoft Windows and Linux community. In building recommendation engine, you have to understand user/community, model their behavior, analyze the interaction and then present them with recommendations in on-line and off-line mode. It can turn out to be a complex setup considering we have to tap Hadoop modules and enact them with right approach and algorithm.
If you want to build a recommender using hybrid approach as mentioned above, you can use free KIJI Framework available from http://www.kiji.org/ . If you want to know how to build a Pearson Collaboration based recomemnder using Microsoft technology, find it at http://www.codeproject.com/Articles/620717/Building-A-Recommendation-Engine-Machine-Learning .
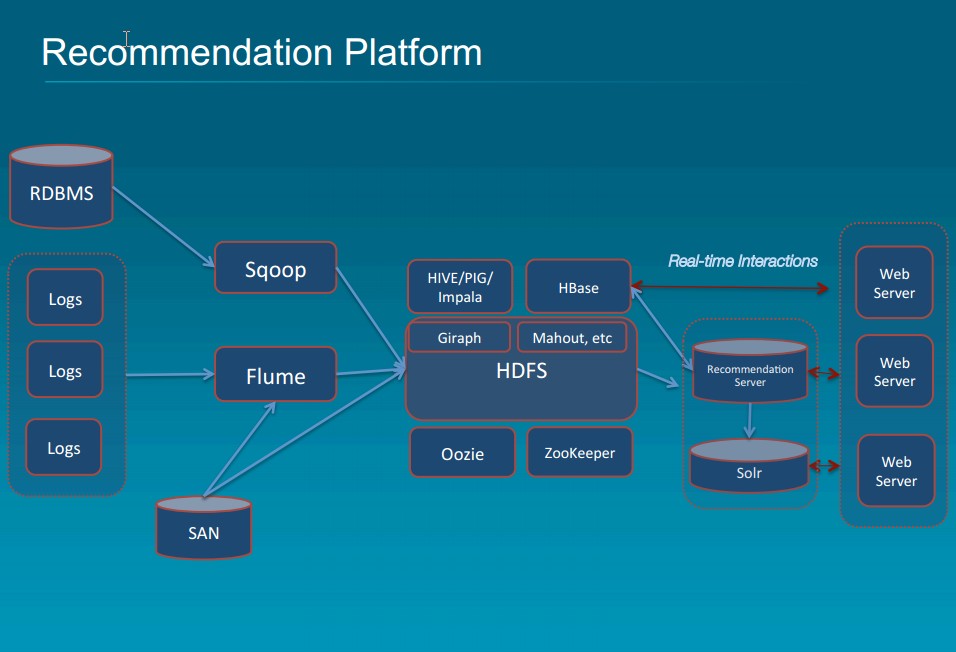
I now give an example of recommendation platform promoted by Cloudera. Here, real time recommendations emanate from the recommendation server while the real time interactions are recorded into Hbase. Apache Giraph is used to calculate matrix of similarity to enable collaborative filtering. Mahout has built in algorithms for clustering, alternating least square etc. The input interaction data, Solr indexes and Mahout results constitute the final recommendation to the user.
In this blog, I give an overview of the recommendation engines widely used in Big Data applications. I have reviewed several articles on the web and now write the blog. With Big Data in limelight for sometime now, there is emphasis on the value aspect of Big Data and how to extract it. Not to our surprise, these engines are workhorses and extract value from big data if you consider now value as 4th V after 3Vs of Big Data i.e Volume, Velocity and Variety.
Recommendation systems are quite popular among shopping sites and social network these days. How do they do it ? Basically, the user interaction data available from items and products in shopping sites and social networks are enough information to build a recommendation engine using classic techniques such as Collaborative Filtering. We know map-reduce is a powerful technique for numerical computation and specially when you have to compute large data sets on Hadoop. The numerical computation is foundation of algorithms used to recommend. Cloudera Platform that combines Hadoop framework and Mahout ( algorithms ) is given below.
At its core, recommendation engines sort through massive amounts of data to identify potential user preferences. Recommendation systems changed the way inanimate websites communicate with their users. Rather than providing a static experience in which users search for and potentially buy products, recommender systems increase interaction to provide a richer experience. If the recommendation benefits a supplier, the engine provider i.e recommendation platform owner benefits financially as well. Recommender systems can identify recommendations autonomously for individual users based on past purchases and searches, and on other users' current behavior. This article introduces you to recommender systems and the algorithms that they implement. It also covers how it is being implemented, with examples from open source, Microsoft and Cloudera.
Examples of Recommendation Engines:
LinkedIn, the business-oriented social networking site, forms recommendations for people you might know, jobs you might like, groups you might want to follow, or companies you might be interested in. LinkedIn uses Apache Hadoop to build its specialized collaborative-filtering capabilities.
Amazon, the popular e-commerce site, uses content-based recommendation. When you select an item to purchase, Amazon recommends other items other users purchased based on that original item (as a matrix of item-to-likelihood-of-next-item purchase). Amazon patented this behavior, called item-to-item collaborative filtering.
Hulu, a streaming-video website, uses a recommendation engine to identify content that might be of interest to users. It also uses (offline) item-based collaborative filtering with Hadoop to scale the processing of massive amounts of data. Details of Hulu's online and offline ItemCF architecture are publicly available.
Netflix, the video rental and streaming service, is a famous example. In 2006, Netflix held a competition to improve its recommendation system, Cinematch. In 2009, three teams combined to build an ensemble of 107 recommendation algorithms that resulted in a single prediction. This ensemble proved to be the key to improving predictive accuracy, and the combined team won the prize.
Other sites that incorporate recommendation engines include Facebook, Twitter, Google, MySpace, Last.fm, Del.icio.us, Pandora, Goodreads, and your favorite online news site. Use of a recommendation engine is becoming a standard element of a modern web presence.
Basic Approaches
Most recommender systems take either of two basic approaches: collaborative filtering or content-based filtering.
Other approaches (such as hybrid approaches) also exist.
Collaborative filtering
Collaborative filtering arrives at a recommendation that's based on a model of prior user behavior. The model can be constructed solely from a single user's behavior or — more effectively — also from the behavior of other users who have similar traits. When it takes other users' behavior into account, collaborative filtering uses group knowledge to form a recommendation based on like users. In essence, recommendations are based on an automatic collaboration of multiple users and filtered on those who exhibit similar preferences or behaviors.
For example, suppose you're building a website to recommend blogs. By using the information from many users who subscribe to and read blogs, you can group those users based on their preferences. For example, you can group together users who read several of the same blogs. From this information, you identify the most popular blogs that are read by that group. Then — for a particular user in the group — you recommend the most popular blog that he or she neither reads nor subscribes to.
Another way to view these relationships is based on their similarities and differences, as illustrated in the Venn diagram. The similarities define (based on the particular algorithm used) how to group users who have similar interests. The differences are opportunities that can be used for recommendation — applied through a filter of popularity or likes.
Content-based filtering
Content-based filtering constructs a recommendation on the basis of a user's behavior. For example, this approach might use historical browsing information, such as which blogs the user reads and the characteristics of those blogs. If a user commonly reads articles about Linux or is likely to leave comments on blogs about software engineering, content-based filtering can use this history to identify and recommend similar content (articles on Linux or other blogs about software engineering). This content can be manually defined or automatically extracted based on other similarity methods.
Hybrid Filtering
Hybrid approaches that combine collaborative and content-based filtering are also increasing the efficiency (and complexity) of recommender systems. A simple example of a hybrid system could use combined approaches mentioned above. Incorporating the results of collaborative and content-based filtering creates the potential for a more accurate recommendation. The hybrid approach could also be used to address collaborative filtering that starts with sparse data — known as cold start— by enabling the results to be weighted initially toward content-based filtering, then shifting the weight toward collaborative filtering as the available user data set matures.
Recommendation Engine Algorithms
As demonstrated by the winning approach for the Netflix prize, many algorithmic approaches are available for recommendation engines. Results can differ based on the problem the algorithm is designed to solve or the relationships that are present in the data. Many of the algorithms come from the field of machine learning, a sub-field of artificial intelligence that produces algorithms for learning, prediction, and decision-making.
Pearson correlation
Similarity between two users (and their attributes, such as articles read from a collection of blogs) can be accurately calculated with the Pearson correlation. This algorithm measures the linear dependence between two variables (or users) as a function of their attributes. But it doesn't calculate this measure over the entire population of users. Instead, the population must be filtered down to neighborhoods based on a higher-level similarity metric, such as reading similar blogs.
The Pearson correlation, which is widely used in research, is a popular algorithm for collaborative filtering.
Clustering
Clustering algorithms are a form of unsupervised learning that can find structure in a set of seemingly random (or unlabeled) data. In general, they work by identifying similarities among items, such as blog readers, by calculating their distance from other items in a feature space. (Features in a feature space could represent the number of articles read in a set of blogs, time spent on articles, comments on blogs etc. .) The number of independent features defines the dimensionality of the space. If items are "close" together, they can be joined in a cluster.
Many clustering algorithms exist. The simplest one is k-means, which partitions items into k clusters. Initially, the items are randomly placed into clusters. Then, a centroid (or center) is calculated for each cluster as a function of its members. Each item's distance from the centroids is then checked. If an item is found to be closer to another cluster, it's moved to that cluster. Centroids are recalculated each time all item distances are checked. When stability is reached (that is, when no items move during an iteration), the set is properly clustered, and the algorithm ends.
Calculating the distance between two objects can be difficult to visualize. One common method is to treat each item as a multidimensional vector and calculate the distance by using the Euclidean algorithm. Other clustering variants include the Adaptive Resonance Theory (ART) family, Fuzzy C-means, and Expectation-Maximization (probabilistic clustering), to name a few.
Other algorithms
Many algorithms — and an even larger set of variations of those algorithms — exist for recommendation engines. Some that have been used successfully include:
Bayesian Belief Nets, which can be visualized as a directed acyclic graph, with arcs representing the associated probabilities among the variables.
Markov chains, which take a similar approach to Bayesian Belief Nets but treat the recommendation problem as sequential optimization instead of simply prediction.
Rocchio classification (developed with the Vector Space Model), which exploits feedback of the item relevance to improve recommendation accuracy.
Building a Recommendation Engine
There are several optimizations we can do in those scripts such as Numpy vectorizations , R packages etc. for computing the similarities between items, interests and so on. These similarities when applied to a model emit recommendations for the user on-line ( Solr ) or off-line ( Hbase/Impala ). Hadoop constitutes an integral part of a big data driven recommendation engines of today.
There are many open source offerings to build recommendation engines. I hereby give examples that cover both Microsoft Windows and Linux community. In building recommendation engine, you have to understand user/community, model their behavior, analyze the interaction and then present them with recommendations in on-line and off-line mode. It can turn out to be a complex setup considering we have to tap Hadoop modules and enact them with right approach and algorithm.
If you want to build a recommender using hybrid approach as mentioned above, you can use free KIJI Framework available from http://www.kiji.org/ . If you want to know how to build a Pearson Collaboration based recomemnder using Microsoft technology, find it at http://www.codeproject.com/Articles/620717/Building-A-Recommendation-Engine-Machine-Learning .
I now give an example of recommendation platform promoted by Cloudera. Here, real time recommendations emanate from the recommendation server while the real time interactions are recorded into Hbase. Apache Giraph is used to calculate matrix of similarity to enable collaborative filtering. Mahout has built in algorithms for clustering, alternating least square etc. The input interaction data, Solr indexes and Mahout results constitute the final recommendation to the user.
Conclusion
As you know by now, recommender systems take data collected on existing user behaviors, and use it to determine what users might also like. It’s a very technical version of what humans do intuitively—we might recommend an ice cream shop to a friend with a sweet tooth, but a coffee place to another friend who is avoiding carbs. By using past behavior of a large number of people, we can predict the taste preferences of an individual or community. Recommendation engines are value drivers for Big Data applications.
As you know by now, recommender systems take data collected on existing user behaviors, and use it to determine what users might also like. It’s a very technical version of what humans do intuitively—we might recommend an ice cream shop to a friend with a sweet tooth, but a coffee place to another friend who is avoiding carbs. By using past behavior of a large number of people, we can predict the taste preferences of an individual or community. Recommendation engines are value drivers for Big Data applications.
 RSS Feed
RSS Feed
